
Startup Opportunities: Generative Idea Creation
Generative knowledge creation and the questions around how we create more and better ideas for humanity.

The concept of ideas being trumped by execution in the startup world is so prevalent that there is no single adage to capture it. It is such a common idea that I could have opened with quotes from any one of: Jobs, Stravinsky, Neistat, Goethe, Ma (Pony), Luckey - this eclectic list could go on indefinitely.
While the sentiment of all these great thinkers is entirely correct, it also remains true that ideas are a prerequisite for anything to be executed on top of.
In an age where increasingly intelligent machines are reducing the cost and pace of execution at a rate of knots, the demand for big ideas to solve both objective (i.e scientific) and subjective (i.e humanistic) functions in our world becomes ever more apparent.
In 2018, USV’s Nick Grossman and Dani Grant wrote a now canonical article titled ‘The Myth of the Infrastructure Phase’. This article broke down the cycles by which new apps tend to appear en masse more or less right off the back of the development of the infrastructural foundations necessary for those apps to exist. To use their words:
“First, apps inspire infrastructure. Then that infrastructure enables new apps.”
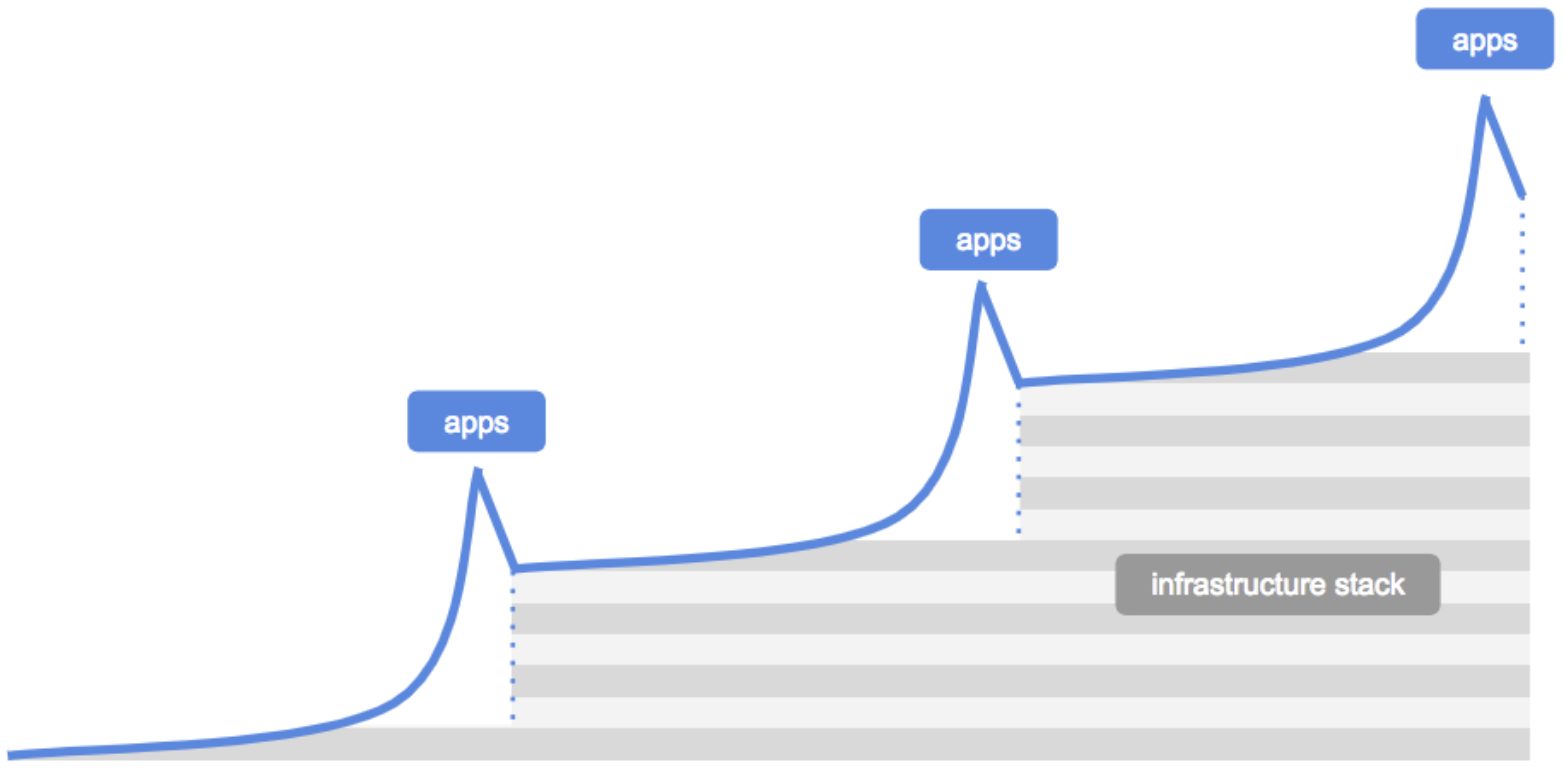
We live at a critical juncture in human history where our species is fast becoming the second best producers of ideas. For this reason, it is worth taking a step back from Grossman and Grant’s theory of the infrastructure stack and stripping it all the way back to ‘ideafrastructure’.
Where the infrastructure-app cycle visualises incremental improvements in technology over time, the ideafrastructure cycle appears incremental but in practice delivers complete transformations in human output and wellbeing as each new inflection point is reached.
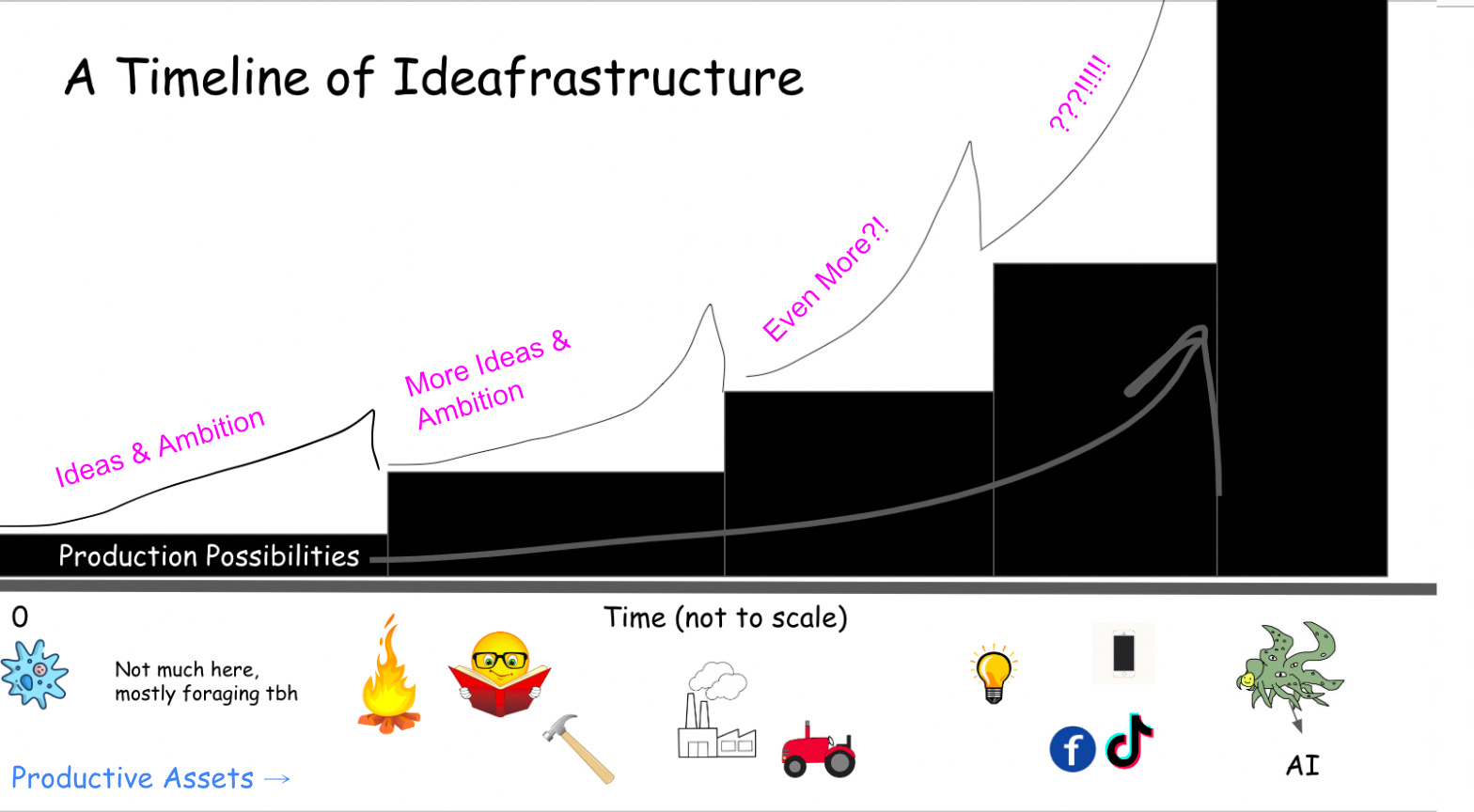
The reason that the ideafrastructure cycle can appear incremental as in the diagram above is because of the composability of ideas. New idea generation is by-and-large a function of the cross-pollination of two or more pre-existing ideas. In reality, composability =! incrementalism. The product of two cross-pollinating ideas in our case can have entirely transformative impacts on productive capacity.
As our powers of execution expand, the ambitiousness and size of the ideas needed to level up collective surplus grows to fill these new capabilities and push them further.
This is a weird kind of intellectual Jevon’s Paradox. As we improve the efficiency by which we create new things to improve our lives, our satisfaction seems to diminish. More creative and ambitious ways to increase our expected wellbeing pop up to fill the new capabilities enabled by new technology.
Once the capacity of the latest generation of productive assets to improve wellbeing has been exhausted, a new generation of idea takes its place and inspires new productive assets altogether (or vice versa). Intentionally or not, the curves in USV’s infrastructure framework provide an interesting way of observing this.
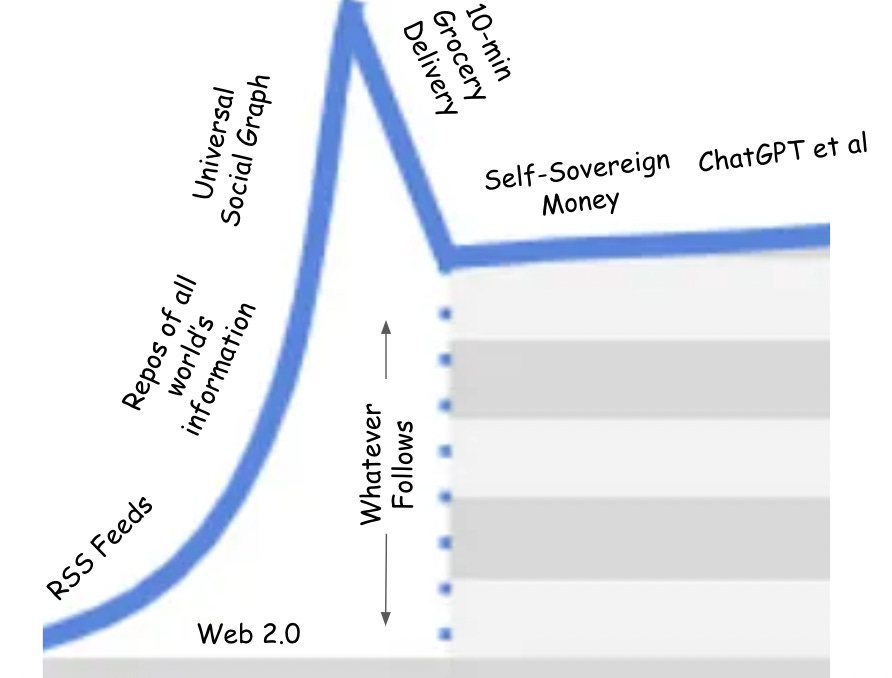
Ideas lay the groundwork for foundational changes in innovation cycles by enhancing our productive possibilities. In turn, improved production possibilities expand the ambition and scope of our ideas to drive even more advances in production and wellbeing.
Now that I have had the chance to try and explain why we want/need more ideas, the practical question: how do we make more?
What constitutes an Idea?
Many people have tried asserting different answers to the above question. Some of them are more assertive than others (ironically, the most assertive ideas about ideas are from some of history’s most prominent idea-benders - the ancient philosophers).
For the sake of this piece, I will follow two similar definitions that I think best fit the context of ideas as they apply to entrepreneurship. Those explanations are as follows:
“An idea is a concept, thought or representation used to describe or explain something.”
“An idea involves the synthesis of existing knowledge or concepts in a novel or innovative way, leading to new insights or perspectives. It can be a solution to a problem, a hypothesis to be tested, a design for a product or system, a philosophical concept, an artistic expression, or a vision for the future.”
The Market for Ideas Today
The would-be founder in the market for ideas is fortunate and unfortunate in equal measure. Fortunate, because they have the pleasure of competing against some of the most rigid, unprogressive institutions on the face of the earth.
Unfortunately, these institutions hold significant power in the public domain and an entrenched position in the marketplace of ideas. If having a marketplace for ideas dominated by a small number of institutions sounds paradoxical, that’s because it is.
IBISWorld values the market for scientific research & development (both academic and institutional) at $227.5bn annually. This covers the functions of research & discovery, peer review & validation, IP transfers, contributions to policy formation and much more.
Because of the foundational role that research plays in any market (being the basis for technological development and all), its disproportionately large problems have disproportionately large flow-on effects. To name but a few:
Inaccessibility. Multibillion dollar institutions like Elsevier, Harvard, thrive on a price-making ability driven through manufactured scarcity. As mentioned above, ideas are composable. By close-sourcing this knowledge, the reputed gatekeepers of today’s knowledge are kneecapping the potential growth in production possibilities cited above.
Publication Bias and the Replication Crisis. The incentives for academics are largely geared such that they are remembered for their discoveries. This creates a bias for publishing positive results. Often, these positive results are actually not so positive. But who has time for verifying these when you need to be publishing your own positive results? Incentives are needed to ensure that 1) research is validated and 2) academics are rewarded for producing actually productive research.
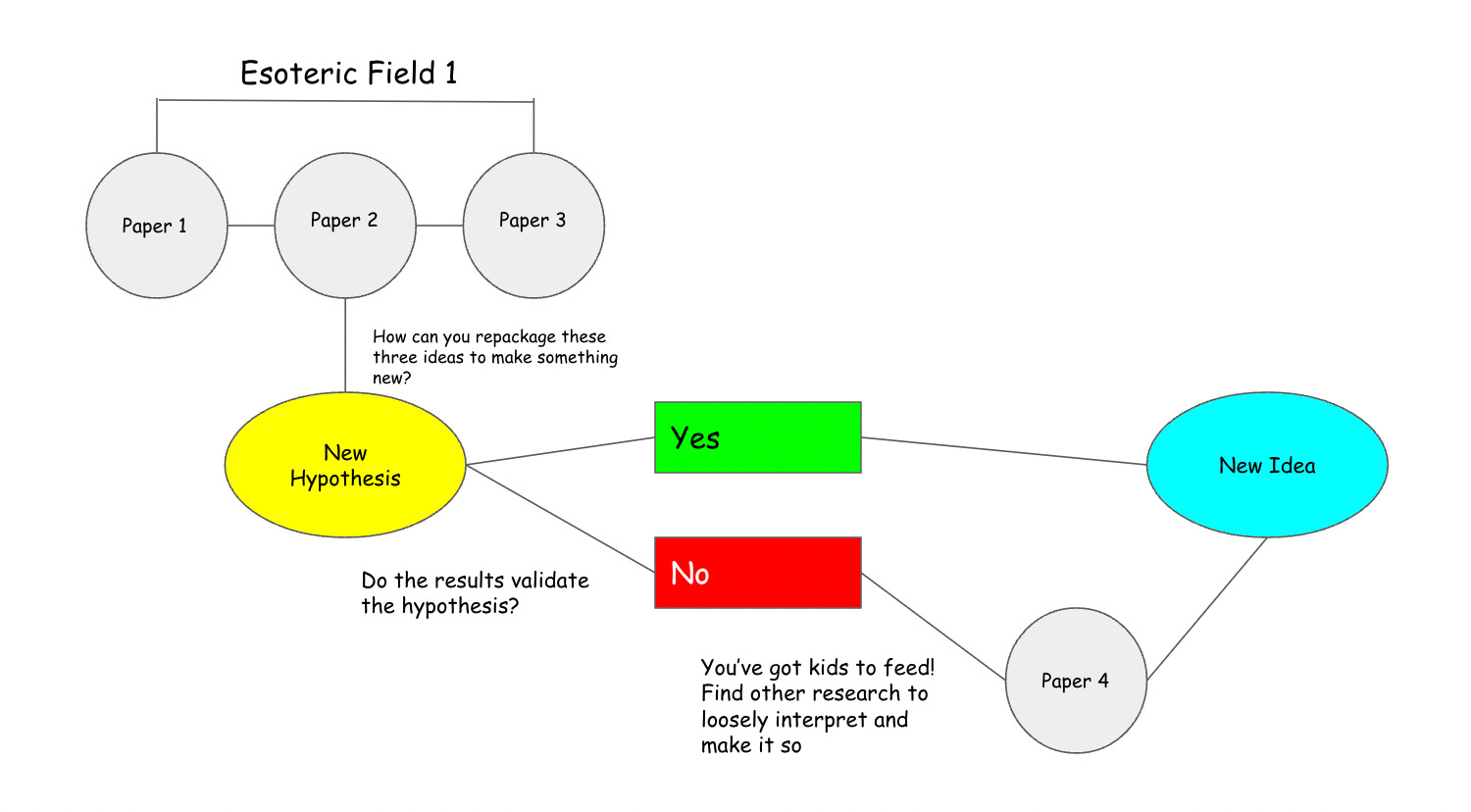
Siloes. To be an expert in any field requires niching down to an extreme degree. The corpus of existing research has been so large for a long enough time that in order to ‘make it’ in academia requires devoting one’s self to a field and taking the time to learn that field inside out. First, the time is spent learning informational precedents inside out. Only after the decades that this step takes can researchers strive to create original knowledge. By the time they’re creating this original knowledge, their existing knowledge base is often so esoteric that it is hard to apply at scale to real-world problems that tend to have problem drivers from multiple disciplines. This creates a culture of academic introspection and incrementalism. More mechanisms need to be in place to break up interdisciplinary boundaries and incentivise cross-pollination of research.
Dissemination & Storytelling. Anyone who has read a research paper from an unfamiliar field knows this one too well. New knowledge, almost by definition, is esoteric. This is not helped by the silo effect described above. Without the ability to sell research through stories that people can relate to and understand, it is hard to drum up the reach needed for the idea to leave a footprint on the world.
If there are so many problems, why are the incumbents still winning?
Economies of Scale. The most obvious example of economies of scale in the market for new knowledge creation is the ability of major institutions to gain access to advanced technology that is difficult to produce or distribute at scale (e.g. large Hadron colliders). Beyond being symbols of progressiveness, these are key resources for driving new discoveries and ideas as outlined in the Ideafrastructure diagram above. A second, derivative version of economies of scale comes through the exclusivity effect that gatekeepers like Elsevier or Taylor & Francis possess.
Legacy Effects. Research institutions, particularly universities, have accumulated immense brand value over time. Harvard is not just a research institution. Like a few other old universities, It has evolved into a universal symbol for intelligence and achievement. This provides institutions like Harvard with both incredible reach and credence - two points that will be expanded upon below.
Which Ideas win?
Once again, a major philosophical question is posed that is very open to interpretation. For the sake of any founders reading this Substack, I will again oversimplify it.

To bastardise Justin Kan’s theory of product above:
The ideas that win are those that achieve the most effective distribution with regards to 1) reach, 2) credence and 3) validity.
Reach refers to the size of the audience that engages with the idea. This is best achieved through the media platforms and KOLs that promote any given idea. For example, the idea of killer AGI. The idea of red wine being an aid for {insert most human problems} appeals to the masses and achieves reach through many a weekend magazine and lifestyle article. Beyond getting the research into the right hands (i.e magazines, newspapers, Twitter KOLs, non-fiction books), a key part of achieving reach through research is via storytelling. Research around red wine works because it’s easy to digest and gets hits. Quantum physics less so.
Credence is concerned with the reputation of the institutions and KOLs that originate or promote a given idea. This most obviously applies to the reputations of research institutions and professors that originate new discoveries in research papers, but also appears in less obvious contexts. To borrow the example of red wine extending longevity used above - this argument gained a lot of credence through the empirical evidence lended to it by centenarians who attribute their drinking habits to their longevity.
Validity shares a lot of crossover with credence. Validity here refers to the replicability of ideas to ensure their truth in practice. This is a key area where science suffers today. The incentives for scientists today revolve around producing ideas to achieve acclaim. If protocols were to come online that take their place as the pre-eminent producers of knowledge, it is my belief that a larger portion of scientific practice can be devoted to validating the ideas of others.
In designing generative knowledge creators, some of the major long-term questions that need to be asked will be around how to balance and optimise this triumvirate in order to ensure that new ideas can be distributed effectively at scale whilst also remaining true.
The more replicable ideas are distributed at scale, the more validity will be optimised and the more trust will be instilled in synthetic new knowledge.
The Future of Ideas
Different Forms of Ideas
Beofre going deeper, a breakdown of the essential ingredients for idea-generation protocols. Taking the bolded wording from the definitions used above, we can divide the idea of the idea into varying levels of actionability from a product development perspective.
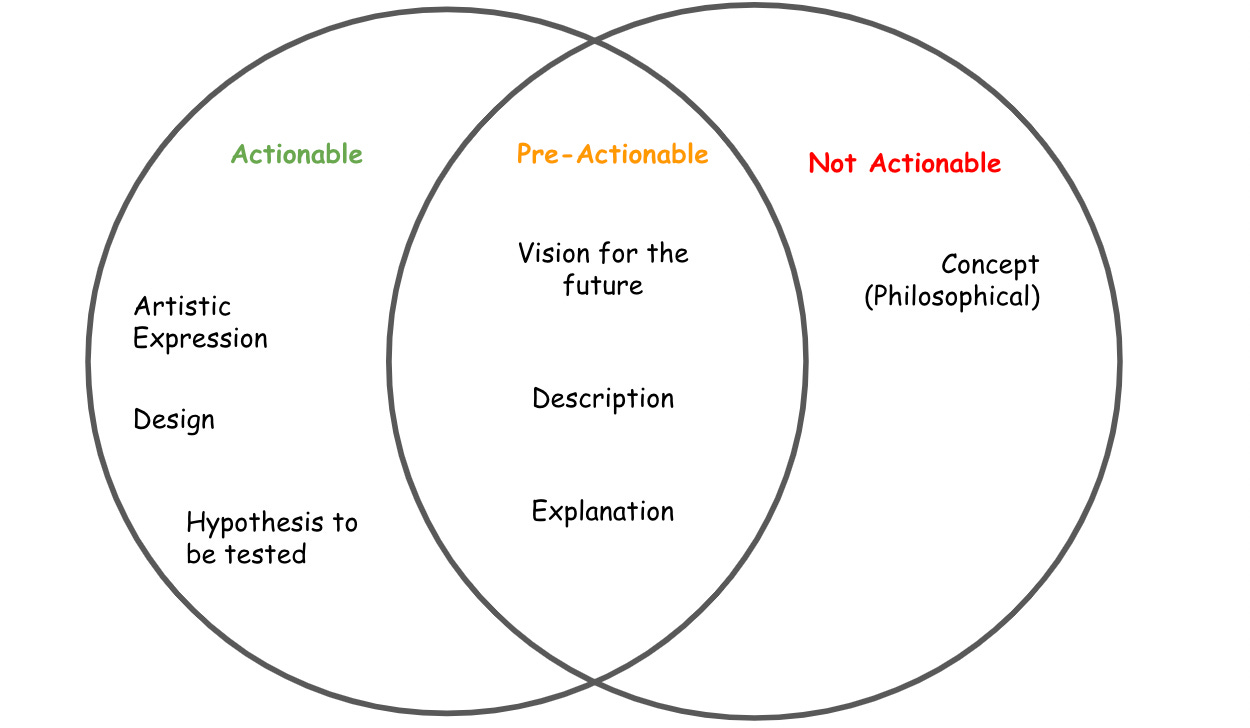
For the sake of the theme of ‘Requests for Startups’ as a newsletter, I intend to focus on the leftmost items on the venn diagram above to help inspire would-be ideamakers. That is not to discount the forms of ideas covered elsewhere as many of them are also necessary ingredients to the next generation of idea-creation protocols.
The aim of condensing the components of what makes an idea are ultimately to help define the objective functions of future products & protocols who specialise in synthesising, judging, distributing and creating competitions for ideas.
What is important in each of these potential functions of new idea-centric products?
Synthesis
The current methods of knowledge creation practiced in academia and corporate R&D facilities follow very straightforward processes. Hypotheses are made around potential outcomes of an experiment based on previous knowledge, tested in a laboratory setting and then validated again against the pre-existing knowledge base. This is essentially how new ideas are rubber-stamped today. The dependence of this system on previous citation, often within a single field, fosters incrementalism.
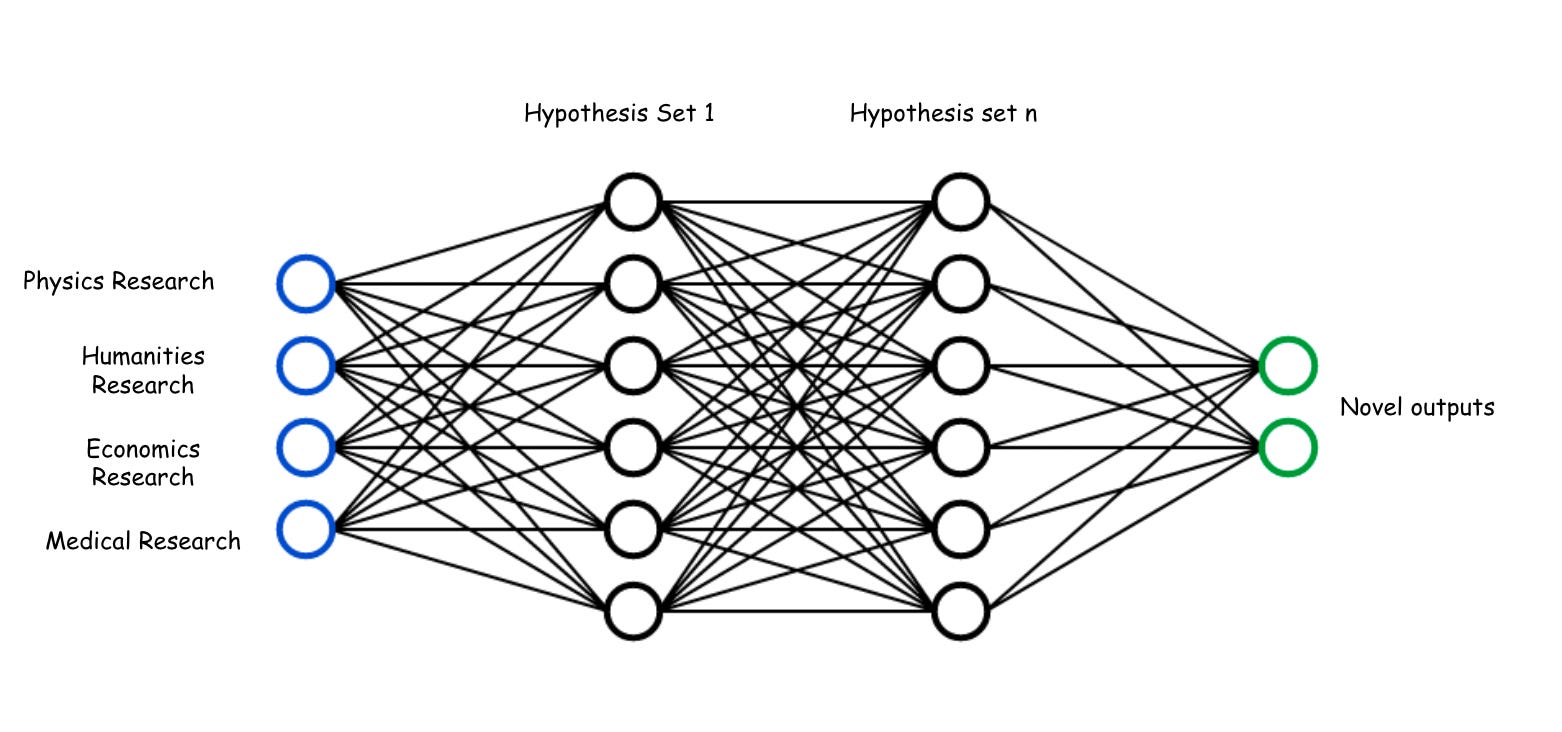
What if methods for new knowledge creation occurred in a manner similar to which a neural network operates? Two fields of knowledge are thrown in as inputs, with all pre-existing research and ideas comingling with one another to develop a massive array of potential hypotheses. Humans or agents can enter a marketplace to vote on the potential impacts of any given hypothesis, with those ‘winners’ being submitted for validation and testing in laboratories.
The function of ideation is outsourced to the machines, whilst humans (for the time being) are still required in the loop for the physical validation of these ideas.
Competition
How should a marketplace be designed to evaluate the potential future impacts of new ideas - whether human or machine generated?
The most common idea to date has been the idea of prediction markets, first credited to Robin Hanson. This is how Hanson views the application of prediction markets to science:
Imagine a betting pool or market on most disputed science questions, with the going odds available to the popular media, and treated socially as the current academic consensus. Imagine that academics are expected to "put up or shut up" and accompany claims with at least token bets, and that statistics are collected on how well people do. Imagine that funding agencies subsidize pools on questions of interest to them, and that research labs pay for much of their research with winnings from previous pools. And imagine that anyone could play, either to take a stand on an important issue, or to insure against technological risk.
This would be an "idea futures" market, which I offer as an alternative to existing academic social institutions. Somewhat like a corn futures market, where one can bet on the future price of corn, here one bets on the future settlement of a present scientific controversy. This is admittedly an unusual suggestion. But consider what might happen.
Inspired by Hanson, the Rosetta protocol (disclaimer: incubated at Hansa) aims to create a market for knowledge whereby researchers upload papers and vote on the possible future effects of it. This creates an incentive for replication as other researchers/financial professionals can gain a financial advantage by proving or disproving the current validity of the research. The rewards from future research are distributed 1) to those who staked a vote on the winning side of the argument, 2) to the researchers who posited the argument and 3) to the precedent researchers cited as contributors to the researcher’s idea.
Storytelling
Many a non-fiction writer (see: Gladwell, Harari, Taleb) has made a killing by interweaving academic knowledge with experiences in the real-world to create digestible ideas for the layman. These are prominent literary careers built off the back of arbitraging the obnoxious tendency of research papers to be virtually incomprehensible.
With the expanding context windows available in today’s LLMs, the scope for summarising and reframing research in a real-world context is becoming infinitely easier. Finding broadly applicable examples and affects to apply to once esoteric research becomes infinitely easier.
We can also have markets for how research stories are told in order to elicit the greatest public interest whilst not compromising the integrity of the actual ideas themselves.
Twitter operates as the largest story marketplace today - what if there were new media platforms that replaced social’s currency of likes and follows with monetary incentives for understanding and communicating new knowledge.
Besides the obvious educational impacts this may have, better stories also serve the function of condensing complex research into easy-to-digest logic that can be used as inspiration for product development.
Commercialisation
Bill Janeway has a strong claim to being the godfather of commercialisation theory in the startup world. His claim (reflected by Marc Andreesen here) is that any startup innovation can be traced to basic (often federal) research funding from as long as 50 years prior waiting to be productised. This means that today, there is a full and growing repository of insights waiting to be converted into entrepreneurial opportunity.
With the proliferation of autonomous agents that are already taking on large portions of roles in (admittedly simple) startups, how far away could we be from near instant commercialisation or commercial testing of novel ideas?
Picture this. A researcher or neural network-based hypothesis creator posits a novel idea. A storytelling protocol summarises the research and turns it into a digestible story that is matched to existing customer needs - these needs can be determined by media sentiment analysis or from some other form of intuition.
From here, a human (or autonomous) manager can segment the key tasks or functions to be completed in order to find the best method for this research to be productised based on the market needs identified above.
This can trigger a task execution loop spanning years or even decades to ensure the consistent growth of the product/business/software/protocol. These loops can be monitored by a single human manager overseeing its operation. Rewards can be distributed to all of those who contributed research in the training data used by the agent to breakdown the product strategy at the beginning.
In Summary
Requests for Startups:
Genuine, No BS Markets for new knowledge creation. This concerns both knowledge made ‘organically’ by today’s scientists or hypothesised ‘synthetically’ via neural networks trained on the existing corpus of research. How can we a) allow researchers to have skin in the game to vote on the potential impacts of their research.
Autonomous Storytellers. There are volumes upon volumes of research in existence that are i) hard for entrepreneurs to understand and ii) difficult to commercialise by turning into product & marketing logic. The capabilities of LLMs even today to summarise and reframe arguments means that this unnecessary complexity can be a thing of the past. Can anyone build a living protocol that scrapes & trains on popular recent research on arXiv or other open-source research platforms, combines ideas and retells them as stories that would-be founders can turn into solutions to problems?
Marco Mascorro has already made some inroads with the paper summariser arXiv GPT. What does this look like if it goes a step further and finds stories that interweave between different fields and identifies the problems they may be able to solve?
Pseudo-Laboratories. What if methods for new knowledge creation occurred in a manner similar to which a neural network operates? Two fields of knowledge are thrown in as inputs, with all pre-existing research and ideas comingling with one another to develop a massive array of potential hypotheses. Humans or agents can enter a marketplace to vote on the potential impacts of any given hypothesis, with those ‘winners’ being submitted for validation and testing in laboratories.